
Introduction
In just a few recent months, the tech world has been taken by storm by AI models like ChatGPT, GPT-4, DALLE-2, and Midjourney. These AI models have genuinely elicited wow reactions from users. Everywhere you turn, there's talk about them. Has the new era of AI already begun? I personally think YES. IT HAS TRULY BEGUN. For those of us in this field, there's so much to ponder and consider. Honestly, I've spent a lot of time reflecting on AI's future direction. Things are moving so fast that if we don't take them seriously, we might be left behind. AI models have evolved impressively, outpacing humans in some tasks. It's a pivotal moment in tech history, and the question is, how should those of us in the AI field, both in academia and the industry, respond? This article represents some perspectives I've gathered from reliable online sources, interspersed with some personal insights. While it might not be exhaustive, I hope it offers a multifaceted view. Let's dive in.
From Perceptrons to Super Large Models
The Humble Perceptron
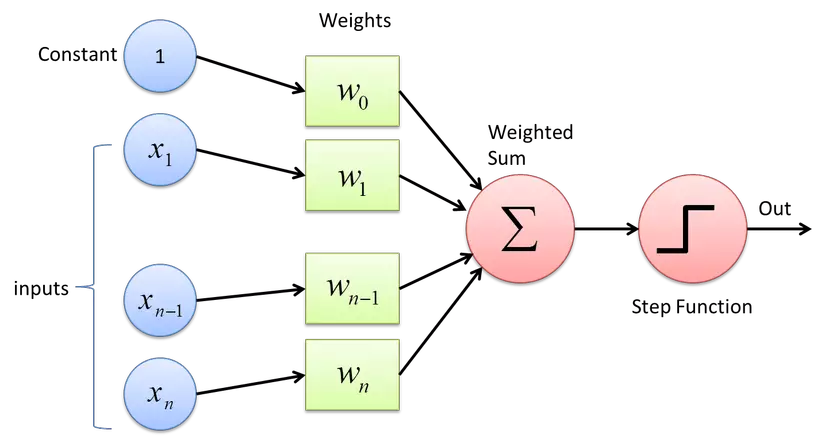
It might be worth delving into the history of neural networks. Back in the 50s and 60s, the perceptron was invented in 1943 and first implemented in 1958 on the IBM 704 computer. Initially, it consisted of just one layer designed for binary image classification tasks. Upon its inception, there was a belief in the budding AI community that the perceptron could be the precursor to an electronic brain capable of tasks like listening, seeing, reading, writing, thinking, and even self-replicating. However, its limitations soon became apparent, and the technology and algorithms of that era weren't advanced enough to realize these aspirations.
Backpropagation and MLP
Neural network history stagnated for several decades until theories about backpropagation emerged, enabling us to train multi-layer perceptrons (MLPs) that could recognize a broader range of classes. This resurgence happened around the mid-1980s. Still, it wasn't until around 2012 that neural networks gained significant practical applications, despite theoretical research progressing in the interim. This slow progress was largely due to the considerable data and computational resources these networks demanded, which computing hardware of the time couldn't meet.
CNNs and GPUs
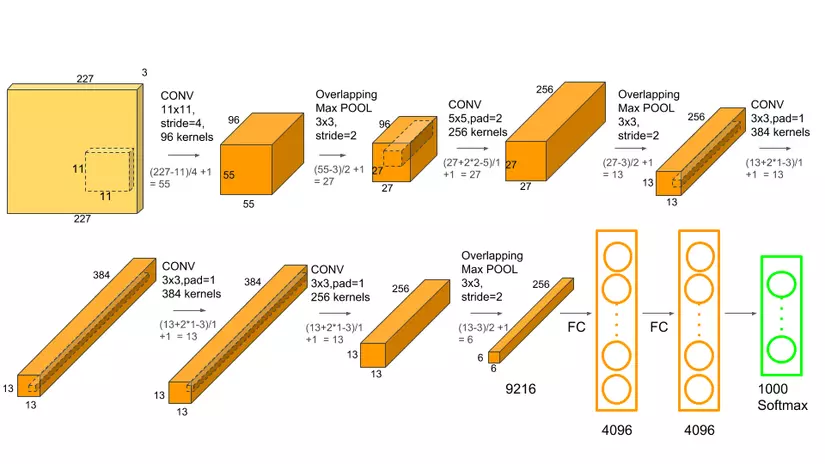
It wasn't until around 2013, marked by the emergence of AlexNet, that convolutional neural networks (CNNs) saw a massive boost, primarily driven by GPU-accelerated training. Using multiple GPUs for training, neural networks could be trained hundreds to thousands of times faster than before. It's evident how significant CNNs have been, especially in computer vision tasks. One of the critical success factors has undoubtedly been the powerful capabilities of GPUs.
Transformers and Self-supervised Learning
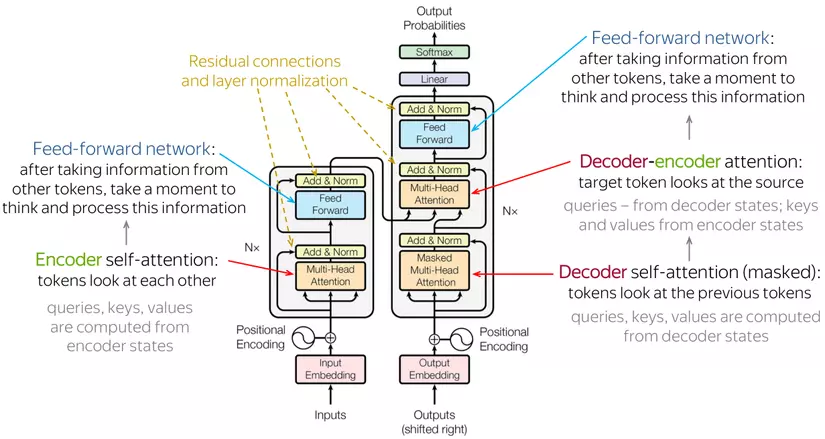
Most of the renowned architectures in today's large models originate from the Transformer. The inherent advantages of the Attention mechanism in Transformers enable a profound understanding of how input components relate to each other. One notable advantage of Transformers over previous RNN-based seq2seq models is their superior parallel processing capabilities, unaffected by sequence lengths. This feature allows Transformers to scale up efficiently with vast data sets and, more importantly, across multi-GPU systems. Such advantages have made it surpass RNNs, especially in tasks involving representation learning for text, images, and audio.
Speaking of representation learning, one can't overlook the advancements in self-supervised learning techniques. This approach has eradicated the need for human-labeled data. Imagine a model that can learn intricate features without any human intervention or influence from human-provided labels. This capability enables super large models to grasp intricate knowledge that even their creators might not fully understand. The success of self-supervised learning becomes even more evident when applied to massive data sets accumulated over decades of internet evolution, enabling the extraction of profoundly intricate information.
Models Keep Growing
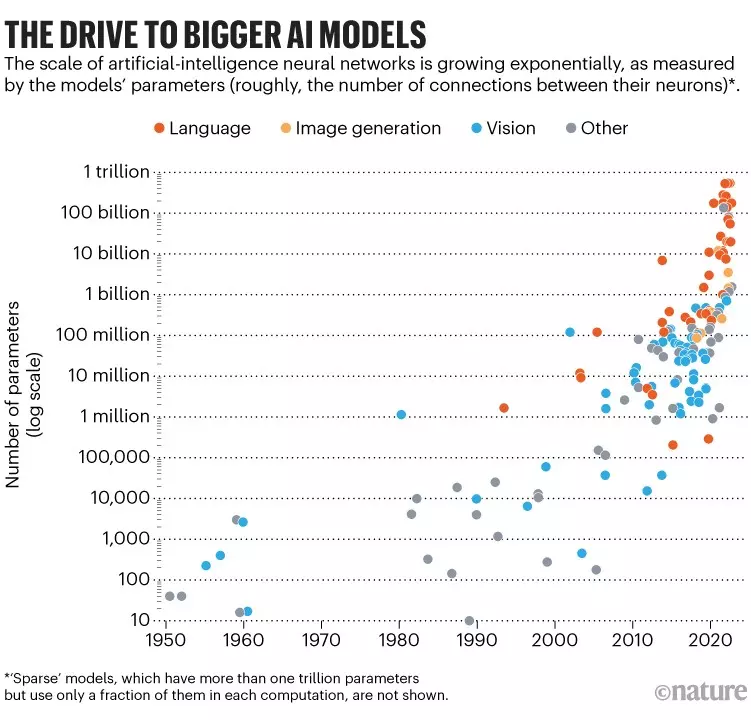
Ever since the Transformer was introduced, its numerous benefits have led to models expanding significantly. Bigger models possess an amazing ability to understand and represent context in a way that smaller models just can't match. This capability is so impressive that even their creators often can't fully grasp what they're doing. Training and operating such expansive models require not just vast datasets but also top-tier computational resources. OpenAI scaled their Kubernetes system to 7500 nodes to support their large language models. The constant growth of these models suggests that AI is becoming the new weapon for BigTech companies. Much like how the U.S. dominated with nuclear weapons in the past, today's AI landscape is being reshaped by BigTech who have control over large models.
So, the question for all of us in tech is, WHAT NOW? Let's delve deeper into this in the following sections.
Academics Must Accept Reality

There's a clear lag by the academic side in this race. As most are aware, nearly all modern Large Language Models (LLMs) originated from the Transformer architecture, a brainchild of Google. It's bitter for Google to realize that surprisingly OpenAI managed to outpace them in building practical large language models based on research they initiated. In today's AI race, lagging by even a day can mean becoming obsolete.
Launching a notable study that garners attention at this time is challenging due to:
- INEVITABLE COMPARISONS WITH LARGE MODELS: People are blown away by the capabilities of large models. Even if you develop something innovative, it's challenging to surpass models trained with millions of dollars. There's even a joke on Twitter suggesting researchers should stop studying and focus on making bigger models.
- SIZE ISN'T GUARANTEED: Excluding researchers in BigTech (a minority), most AI researchers in institutions or universities struggle to train large models. The biggest obstacle, as we all know, is FUNDING. Just wanting a bigger model doesn’t make it so.
- MONEY DOESN'T GUARANTEE TALENT: Even if you sort out the hardware issue, training large models isn't easy. We need experts knowledgeable in both academia and engineering to manage these systems. So, even with funding, labs struggle due to the volatile nature of their teams. Many talented individuals often end up at BigTech companies.
It may sound a bit pessimistic, but accepting the fact that groundbreaking studies are incredibly challenging can be liberating. This mindset suits those content with making minor contributions to their academic journey.
Pursue Niche Avenues

If we focus on fields like NLP or Generative AI, most related tasks are excellently tackled by large models. Despite best efforts, making significant breakthroughs in these areas is tough. Even giants like Google struggle with this. However, there are specific niches BigTech hasn't touched or found worthy of their time. Areas with specialized knowledge, like healthcare, finance, retail, or banking, present unique research opportunities. Addressing narrow domains offers a greater chance of success than competing directly with industry giants.
Stand on the Shoulders of Giants
If training models from scratch seems economically or logistically impossible, leveraging pre-trained models for your purposes can be an excellent research path. Recent studies have shown that models can achieve about 90% of ChatGPT's efficiency but with a smaller size. This benefits the research community as methodologies and source codes are tested and made public.

Addressing the Weaknesses of Large Models
Large models often come with operational complexities and challenges. Addressing the shortcomings of these models, such as training time, model size, or specialized accelerators, is a promising research avenue. Nowadays, there's growing concern about environmental impacts during AI model training and challenges in deploying models on constrained hardware. This represents a significant research opportunity, with potential breakthroughs anticipated in theory, hardware, and software.
Shifting Focus to Applications or Start-ups
In my view, whether it's AI or any other technology, its ultimate goal should serve the end-users. It might cater to a broad audience or a specific group, but it should undoubtedly have a practical application. Of course, not all research will immediately yield direct applications; some might lay the groundwork for future studies. However, if you're a keen-minded researcher, why not pivot your research towards real-world applications and create more products?
Those in the Industry
Swift Applications

It's evident that since the emergence of ChatGPT, there's been a surge in start-ups, indicating the nearing age of AI application. If you're in the industry, you shouldn't miss this chance. Understand its workings and familiarize yourself with the tools and frameworks to optimize large models. These are essential foundations for application development. Personally, I'm surprised at how affordable it is to use large language models like ChatGPT. It's puzzling how they profit with such price points, but it undoubtedly heralds a new era for software where integrating AI becomes seamless.
Focusing on Specific Domains or Private Data

Many companies or operations can't directly implement large language models into their product logic due to security concerns. Thus, an avenue worth exploring is using large language models for private data. For niche domains that require specialized domain knowledge, it's crucial to discover methods to integrate large models into such projects.
Even without implementing these large models, specific domains remain an area that even the giants struggle to fully capture. Hence, equipping yourself with knowledge in these sectors is always valuable.
Augmenting System Architecture for AI
As we all can see, training these large models requires not just hardware resources but also human expertise. Professionals need to understand not just how the models work but also possess advanced engineering skills when training them. Deploying systems with large language models presents challenges requiring in-depth engineering and infrastructure knowledge, especially specific knowledge for individual cloud providers. In the not-so-distant future, customizing and training AI models on complex systems will be inevitable. This demands meticulous preparation. We can't simply react when problems arise, right?

Conclusion
The future of AI will undoubtedly introduce changes to our operations. While there are challenges ahead, they come with a myriad of new opportunities. If you're in the AI field, prepare yourself for the best direction in a journey that, though filled with obstacles, remains utterly fascinating. This article is getting quite long. I look forward to meeting you in upcoming articles.













0 Comments