
Introduction
Hello everyone, today I'll be diving into a topic that's not new but remains consistently hot. That is, what are the commonly asked questions during an AI Engineer interview?. Not every interview will touch on all these questions, as they often depend on the candidate's experience and past projects. After numerous interviews, especially with students, I've compiled a list of 12 of the most valued interview questions in the Deep Learning field. I'm eager to hear your feedback. Let's get started without further ado.
1. Explain the significance of Batch Normalization
This is a fantastic question as it encompasses nearly all the knowledge a candidate should be aware of when working with a neural network model. Answers may vary, but the key points to address are:

Batch Normalization is an effective method when training a neural network model. The primary aim of this method is to normalize the features (output from each layer after passing through activations) to a zero-mean state with a standard deviation of 1. Let's discuss how a non-zero mean affects the training process:
- Firstly, a Non-zero mean implies data doesn't center around the value 0. Instead, data primarily has values greater or lesser than zero. Coupled with the high variance issue, this can lead to extreme large or small data components. This problem is quite common when training deep neural networks. When features are not distributed within stable ranges (with irregular large or small values), it affects the optimization process. As we know, optimizing a neural network requires gradient computations. Suppose a simple computation for a layer is y = (Wx + b); the derivative of y with respect to w would look like: dy = dWx. Thus, the value of x directly influences the gradient's value. Therefore, if x has unstable values, the gradient might become too large or too small, making model learning unstable. Using Batch Normalization allows us to use higher learning rates during training.
- Batch normalization helps prevent the value of x from saturating after passing through non-linear activation functions. It ensures that no activations are excessively high or low. This assists in learning weights that otherwise might never have been adjusted when not using Batch Normalization. It reduces the dependency on initial parameter values.
- Batch Normalization also acts as a form of regularization helping to reduce overfitting. With batch normalization, there's less reliance on dropout, meaning we don't need to worry about losing too much information due to dropped weights. However, it's still beneficial to combine both techniques.
2. Explain the concept and the trade-off relationship between bias and variance?
- Bias can be simply understood as the difference between the average predictions of our model and the actual values we are trying to predict. A model with a high bias pays less attention to the training data, leading it to oversimplify, resulting in poor accuracy on both training and testing sets. This phenomenon is known as Underfitting.
- Variance refers to the dispersion or clustering of the model's output for a particular data point. High variance indicates that the model is paying a lot of attention to the training data, making it less generalizable to unseen data. This results in great performance on the training set but poor performance on the testing set, known as overfitting.
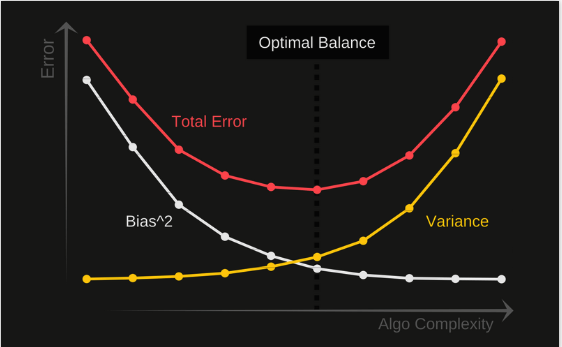
In the provided diagram, the center of the circle represents a perfect prediction model. In reality, it's nearly impossible to find a model that perfect. As we move away from the center, our predictions get worse. The goal is to adjust our model so that most predictions are close to the center of the circle. Balancing between Bias and Variance is crucial. If our model is too simple with few parameters, it might have high bias and low variance. Conversely, a model with many parameters might have high variance and low bias. This balance is the foundation for determining model complexity during algorithm design.
3. Suppose After a Deep Learning Model Identifies 10 Million Face Vectors. How to Quickly Search for a New Face Query?
This question leans towards the practical application of Deep Learning algorithms. The key aspect here is the method of indexing data. It's the final step in applying One Shot Learning for face recognition, yet it's the most crucial for real-world deployment. At its core, for this question, you should start with an overview of face recognition using One Shot Learning. Simply put, it involves turning each face into a vector. Recognizing a new face means finding vectors that are closest (or most similar) to the input face. Typically, a deep learning model with a custom loss function called triplet loss is used for this purpose.
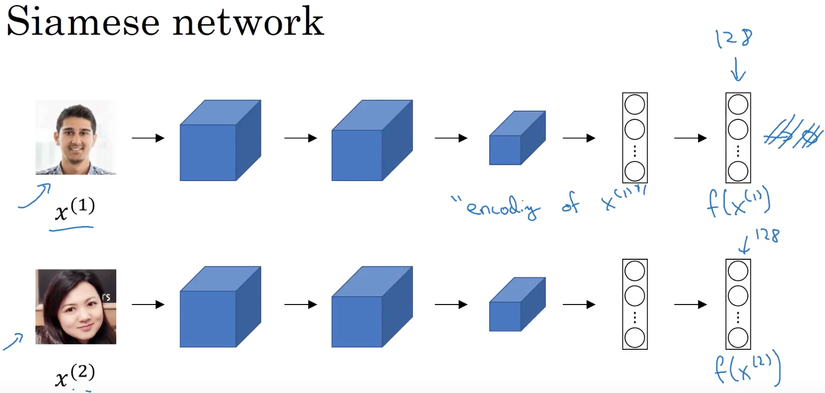
However, as the number of images increases as mentioned, calculating the distance to 10 million vectors every time during recognition isn’t smart. It significantly slows down the system. We need to immediately consider methods for indexing data in the vector space to make querying more efficient. The main idea behind these methods is to divide the data into structures that are easy to query (possibly resembling tree structures). When new data is introduced, querying the tree helps quickly identify the closest vector in a very short time.

There are some methods that can be used for this purpose, such as Locality Sensitive Hashing - LSH, Approximate Nearest Neighbors Oh Yeah - Annoy Indexing, Faiss, etc.
4. In Classification Problems, Can We Fully Trust the Accuracy Metric? Which Metrics Do You Usually Use to Assess Your Model?
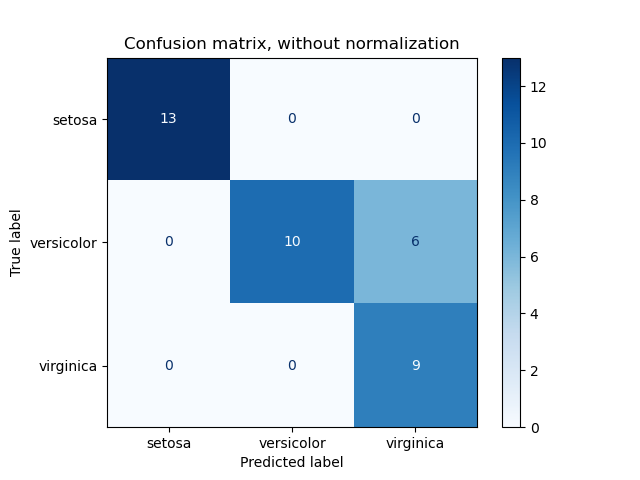
For a classification task, there are various evaluation metrics. For accuracy, the formula simply divides the correctly predicted data points by the total number of data points. While this might sound reasonable, in real-world scenarios with imbalanced data, this metric can be misleading. Suppose we are building a model to predict network attacks (let's assume attack requests constitute about 1 in 100,000 total requests). If the model predicts all requests as normal, the accuracy would still be 99.9999%. This number can't be relied upon in classification models. The above accuracy calculation just tells us the percentage of correctly predicted data without showing how each class is specifically classified. Instead, we can use the Confusion Matrix. Basically, a confusion matrix shows how many actual data points of a class are predicted as belonging to another class.
Furthermore, to represent changes in True Positive and False Positive metrics against different thresholds, we use a graph called the Receiver Operating Characteristic - ROC. Based on the ROC, we can determine the model's effectiveness.
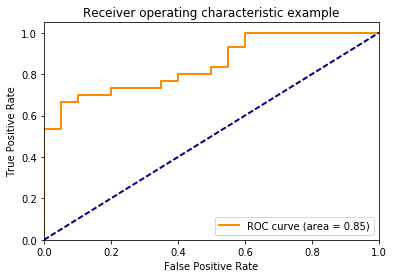
An ideal ROC curve is one where the curve, often in orange, is close to the top-left corner (meaning a high True Positive rate and low False Positive rate). Another measure of a model's effectiveness is the Area Under the Curve beneath the ROC Curve. The higher this area, the more effective the model.
5. How Do You Understand Backpropagation? Explain its Mechanism?
This question aims to test knowledge about how a neural network operates. Here are the main points:
- The forward process, or forward computation, calculates the weights for each layer, resulting in an output, ( yp ). At this stage, the loss function's value is computed, reflecting the model's performance. If the loss isn't optimal, the goal becomes reducing the loss value. Training a neural network essentially minimizes this loss function. The loss function, ( L(yp,yt) ), represents the difference between the model's output ( yp ) and the true label ( yt ).
- To reduce the loss value, we use derivatives. Backpropagation helps calculate the derivative for each layer of the network. Based on these derivatives, optimizers like Adam, SGD, AdaDelta, etc., apply gradient descent to update the network's weights.
- Backpropagation uses the chain rule, also known as the composite function derivative, to compute the gradient for each layer from the last layer to the first.
6. What is the significance of the activation function? What does saturation point mean for activation functions?
Importance of the activation function
Activation functions are designed to break the linearity of neural networks. Think of them as filters deciding whether information should pass through a neuron. During the neural network training process, activation functions play a crucial role in adjusting the gradient of the derivative. Some activation functions like sigmoid, tanh, or ReLU will be discussed in detail later. But, it's essential to realize that the non-linear nature of these functions allows neural networks to learn representations of more complex functions than just using linear ones. Most of these activation functions are continuous and differentiable. This means that a small change in the input results in a slight change in the output, and they have a derivative at every point within their domain. Being able to compute the derivative is critical, as it determines whether our neuron can be trained. Examples of such activation functions include Sigmoid, Softmax, and ReLU.
Saturation regions of the activation function
Non-linear activation functions like Tanh, Sigmoid, and ReLU have saturation regions.
Simply put, the saturation regions of an activation function are ranges where the output value of the function doesn't change, even if the input value does. Two main issues arise from these regions. In the forward direction of the neural network, the output values tend to become similar if the layer values fall within the saturation regions. This phenomenon is known as covariance shifting. The second issue is during the backward direction: the derivative becomes zero within the saturation region, making the network almost untrainable. That's why it's crucial to normalize values around mean zero, as discussed in Batch Normalization.
7. What are the hyperparameters of the model? How do they differ from parameters?
What is a Model Parameter?
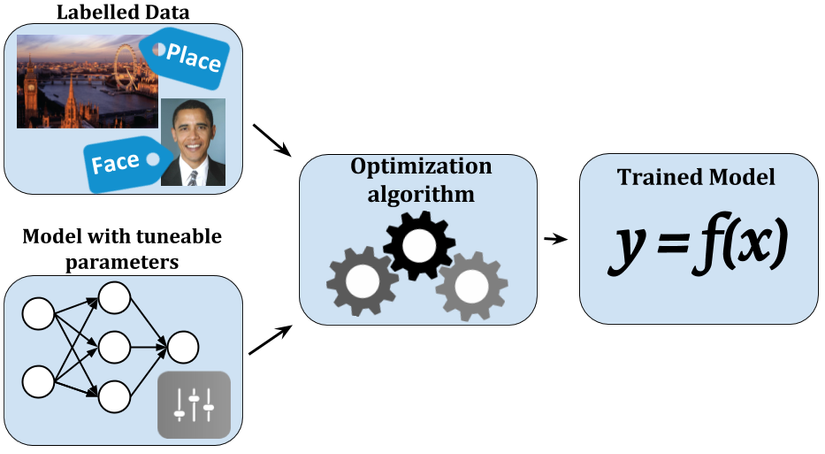
Going back to the basics of Machine Learning, firstly, to work on machine learning, we need a dataset. Without data, what would we use to learn and train, right? After obtaining the data, the machine's task is to find a relationship within this data. Let's assume our data contains weather-related information like humidity, rainfall, temperature, etc., and the machine's task is to correlate these factors with whether our partner is angry or not. It may sound unrelated, but sometimes machine learning does deal with such quirky correlations. Now, let's say we use variable y to denote if our partner is angry or not and variables x1, x2, x3... for weather factors. The relationship can be depicted as:
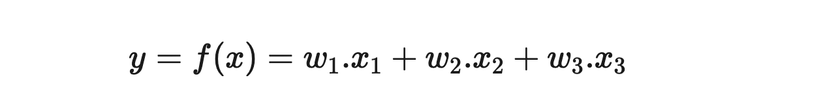
Do you see the coefficients w1, w2, w3...? They represent the relationship between our data and the factor we're looking into. These coefficients are what we call Model Parameters. So, a model parameter can be defined as:
Model Parameters are values generated by the model from training data that represent the relationship between quantities in the data.
So, when we say we've found the best model for a problem, it means we've identified the most suitable Model Parameters based on the available data. Some of its characteristics include:
- Used for predictions with new data
- Represents the model's capability, usually denoted by accuracy
- Directly learned from the training dataset
- Typically not set manually by humans
You might encounter Model Parameters in forms like weights in neural networks, support vectors in SVM, or coefficients in linear or logistic regression algorithms.
What is a Model Hyperparameter?
Due to the habit of translating Hyperparameter as a "super parameter", one might assume it's a beefed-up version of Model Parameter. However, these two are entirely distinct. Unlike Model Parameters, which the model derives from the training data, Model Hyperparameters are entirely external to the model and independent of the training dataset. So, what's their purpose? They have roles like:
- Used during training to help the model identify the best parameters
- Often manually selected by those training the model
- Defined based on certain heuristic strategies
In practice, it's nearly impossible to know the best Model Hyperparameter for a specific problem. Therefore, certain techniques estimate an optimal range for these values, like the coefficient k in the k Nearest Neighbor model, using methods like Grid Search.
Here are some examples of Model Hyperparameters:
- Learning rate during the training of an artificial neural network
- Parameters C and sigma when training a Support Vector Machine
- Coefficient k in the k Nearest Neighbor model
8. What happens when the learning rate is too high or too low?
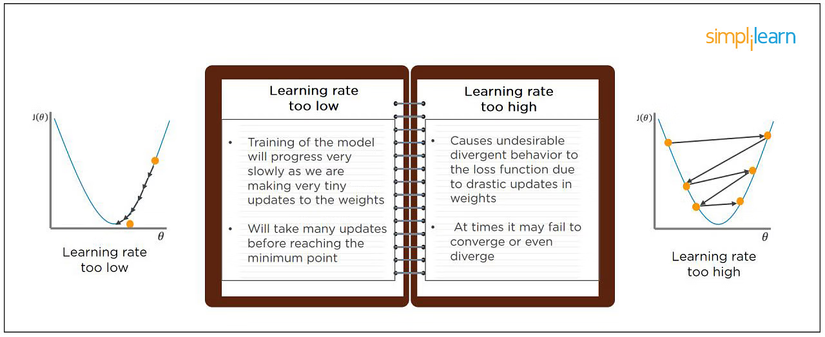
- When the model's learning rate is set too low, the training process takes place very slowly as it has to make tiny updates to the weights. It will require many updates before reaching a local optimum.
- If the learning rate is set too high, the model might struggle to converge due to the overly aggressive weight updates. The model might overshoot the local optimum in just one update step, making it difficult for subsequent updates to return to the optimum point. This can be imagined as the model bouncing back and forth around the optimum point because it jumped too far.
9. When the input image size doubles, how many times does the parameter count of a CNN (Convolutional Neural Network) increase? Why?
This is a question that can easily mislead candidates, as most might think in terms of how many times the parameters of the CNN will increase. However, let's revisit the architecture of the CNN.
It's evident that the parameter count of the CNN model depends on the number and size of the filters, not on the input image size. Hence, even if the image size doubles, it doesn't alter the parameter count of the model.
10. How do you address datasets that are imbalanced?
This question tests a candidate's approach to problems with real-world data. Typically, real data can significantly differ in characteristics and data volume compared to standard datasets. In real-world scenarios, one might come across datasets that are imbalanced, meaning there's a disparity in the number of instances between classes. Here are some techniques to consider:
- Choose the right metric to evaluate the model: The first step is to pick the right metric. Using accuracy for evaluation in an imbalanced dataset can be misleading. Suitable metrics to consider include Precision, Recall, F1 Score, AUC.
- Resample the training dataset: Beyond choosing different evaluation criteria, one can employ techniques to generate varied datasets. Two common strategies to produce a balanced dataset from an imbalanced one are Under-sampling and Over-sampling, using methods like repetition, bootstrapping, or SMOTE (Synthetic Minority Over-Sampling Technique).
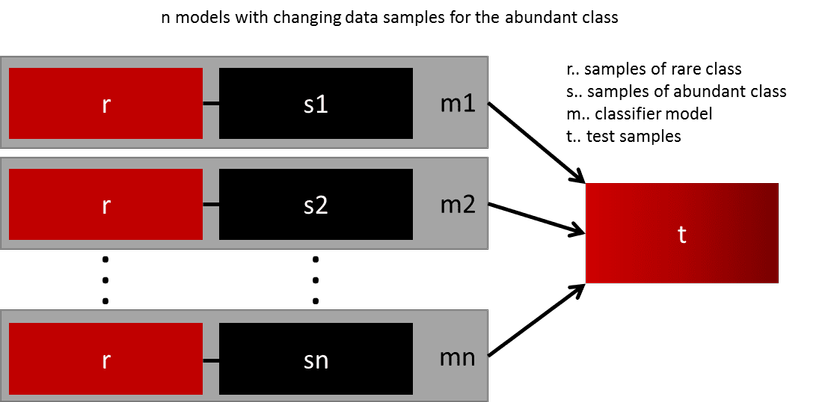
- Ensemble multiple models: It's not always feasible to generate more data in real-world situations. For instance, if you have two classes, with one rare class having 1000 instances and a prevalent class having 10,000 instances. Instead of trying to find 9,000 instances of the rare class to train a model, one might consider training 10 separate models. Each model is trained with 1000 instances from the rare class and 1000 from the prevalent class. Then, ensemble techniques can be used to derive the best result.
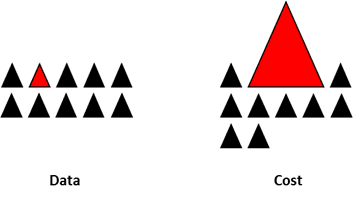
- Redesign the model - cost function: Using penalty techniques to heavily penalize the abundant classes in the cost function helps the model learn the rare class data better. This ensures the loss function better represents the overall distribution among classes.
11. What do the concepts of Epoch, Batch, and Iteration mean in Deep Learning training?
These are fundamental concepts when training a neural network, but in reality, many candidates get confused distinguishing them. Specifically, they can be described as:
- Epoch - Represents one complete pass over the entire dataset (everything fed into the training model).
- Batch - Refers to when we can't process the whole dataset at once, so we divide the dataset into several batches, each consisting of a subset of the data.
- Iteration - The number of batches needed to complete one epoch. For instance, if we have 10,000 images as data and the batch size is 200, then one epoch consists of 50 iterations (10,000 divided by 200).
12. What is the concept of a Data Generator? When do we need it?
It's an essential concept in programming known as the data generation function. This function helps generate data directly to fit into the model in each training batch.

Using this function is extremely beneficial when training with large datasets. It's not always necessary to load the entire dataset into RAM, which could waste memory. Moreover, if the dataset is vast, it can cause memory overflow, and the preprocessing time for input data will increase.
Conclusion
Above are the 12 interview questions on Deep Learning that I frequently ask candidates during interviews. However, depending on each candidate, the way of asking might differ, or there might be spontaneous questions arising from projects that the candidate has worked on. Although this article focuses on technical issues, it's related to interviews, and from my perspective, attitude determines 50% of the interview's success. Hence, besides accumulating knowledge and hard skills, always present yourself with sincerity, ambition, and humility. You'll surely reap success in any conversation. I wish everyone achieves their aspirations. Goodbye and see you in upcoming blogs













0 Comments