
Introduction
Hello everyone! It's been a while since my last piece on the GPT-4 Technical Report by OpenAI. I haven't written about LLM lately, but today, I had to pull another all-nighter to delve into the 76-page LLaMa-2 paper. And I must say, it was totally worth it. After reading it, all I could think of saying was:
This is pure happiness! Long live Meta, and hats off to Mark Zuckerberg.
Enough with the fanboying, let's get back to the main topic. The LLaMa-2 paper is different from the GPT-4 one in several ways:
- Clearly explains all technical concepts, from model architecture, data creation, training methods, evaluation techniques to safety and utility improvements.
- Offers open-source code, especially allowing for commercial use.
- Provides high-quality data for all purposes, from research to model development.
Without further ado, let's dive into the paper's details.
P/S: After finishing this article, I realized it might take you approxiate 35 minutes to read. Sorry about that! I've summarized a 76-page paper for you
Quick Experience
You can quickly test the LLaMa-2 model at this link. With Perplexity's caching techniques combined with the optimizations of LLaMa-2, you'll find it as swift as a rocket. It doesn't feel like interacting with LLM but more like searching on Google. The results are pretty solid, even though I've only tried the 13B version.
What is LLaMa-2?
In short, LLaMa-2 is the successor of LLaMa - a large language model developed by Facebook AI Research and their engineering team. Architecturally, it resembles LLaMa but with added data, quality improvements, and new optimization techniques to enhance performance. This model outperforms other open-source models significantly, and it's entirely open source, including the model, data, and permission for commercial use.
This model was crafted by Facebook AI Research's massive engineering team. Almost 50 people are credited in the paper.

Interestingly, I couldn't find Yann Lecun - one of my idols. Maybe he was busy with another project or perhaps his contributions weren't significant enough to be credited in this paper? Another intriguing observation is the organization's name has changed to GenAI - Meta. Could this be an independent division of FAIR?
Coming back to LLaMa-2, they released two versions: the pretrained LLM LLaMa-2 and a chat-specific version called LLaMa-2-CHAT. Both have variants ranging from 7B to 70B parameters. What sets this model apart from LLaMa-1 is:
- Context length has increased from 2048 to 4096, allowing the model to capture more contextual information.
- The Pretraining corpus expanded by 40% by incorporating more quality data from Meta.
- The Grouped Query Attention technique was employed, enhancing efficiency during inference. You can learn more about it here.
Is it Really Open Source?
In my opinion, LLaMa-2 isn't truly considered open source for the following reasons:
- Firstly, they only provide a fine-tuned model and the training method via a technical report. They don’t provide the training code, the data for training, and most importantly, they don't offer the reward model - which is a crucial component for training RLHF.
- Secondly, there are restrictions for users. For instance, it's applicable only for companies with fewer than 700 million active users per month. This suggests they target smaller businesses and startups.

While it might not be open-source, from a technical perspective, I appreciate their effort. Their technical report contains numerous technical aspects we can learn from. I believe that for the community and small businesses, this represents a significant technological advancement.
Model Architecture
The paper does not detail the model's architecture but reveals that the LLaMa-2 structure follows the standard Transformer architecture and is similar to that of LLaMa-1. So, to better understand LLaMa-2's architecture, we should explore LLaMa's model.
Both LLaMa and LLâM-2 are Generative Pretrained Transformers based on the Transformer architecture. You can refer to its source code here. Some differences compared to the standard GPT architecture are:
- LLaMa uses RMSNorm for input normalization for each transformer layer instead of the output.
- It uses SwiGLU activation instead of ReLu, improving training performance.
- Similar to GPT-Neo-X, LLaMa employs rotary positional embeddings (RoPE) in its network layers.
According to LLaMa-2's paper report, the only architecture modification is the context length size and the use of grouped-query attention. Increasing the context length size allows the model to produce and process more information, which is especially beneficial for understanding long documents. Replacing the standard Transformer's multi-head attention - where many queries can correspond to one key-value projection, with grouped-query attention with eight key-value projections speeds up training. It also makes it easier to increase the model's complexity, batch size, and context length.
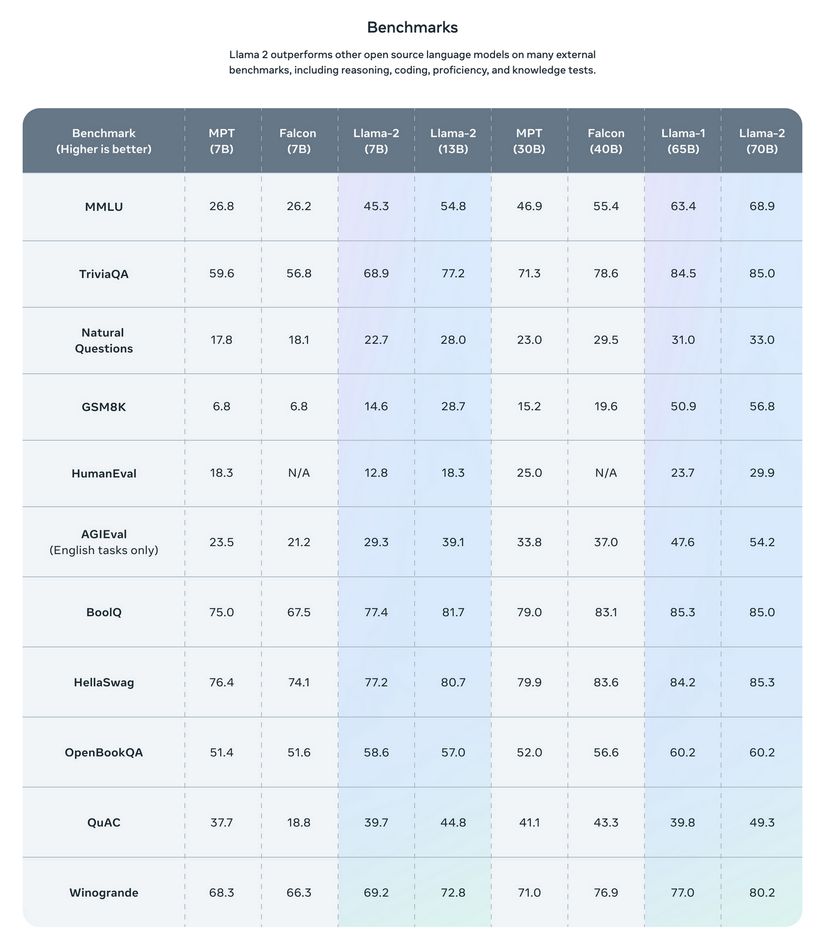
These modifications enable LLaMa-2 to outperform many previous open-source LLM models in various tasks, like Falcon or MPT. I hope that with the move to open-source, we'll soon see LLaMa versions that can compete with GPT-4 and Google Bard.
In general, there isn't much to discuss about this model. Most of the paper focuses on the training method and ensuring the model's safety rather than its architecture. This shows that while model architecture is essential, data processing techniques and training methods are even more critical. Perhaps they didn't want to disclose the trade secrets of the engineers at FAIR regarding model selection and their reasons for such choices. This could be one of the advantages that keeps the FAIR engineering team at the forefront of open-source LLM development.
I also believe that LLM's strength lies in its ability to represent vast amounts of information due to its large model size and training data construction. You can directly refer to LLaMa-2's source code on the official website. There's nothing secret about it. Therefore, there's a recent statement in science that researchers don't need to do anything special; they should focus on making the model large enough since bigger models have beneficial properties that smaller models lack. In essence, it's like brute-forcing with sheer power.
How to Train
The essence of training large language models lies not so much in the model architecture but in the data and the training approach. While we'll delve into data specifics later, let's first touch upon the training technique and the fine-tuning of LLM using the RLHF method. This became the focal point in training LLaMa-2. Even though many had heard about it, the exact implementation remained undisclosed until the LLaMa-2 paper, which shed light on the whole process. In a nutshell, the training and fine-tuning with RLHF are simply OUTSTANDING. For a comprehensive understanding of training with RLHF, one can refer to the provided illustration.
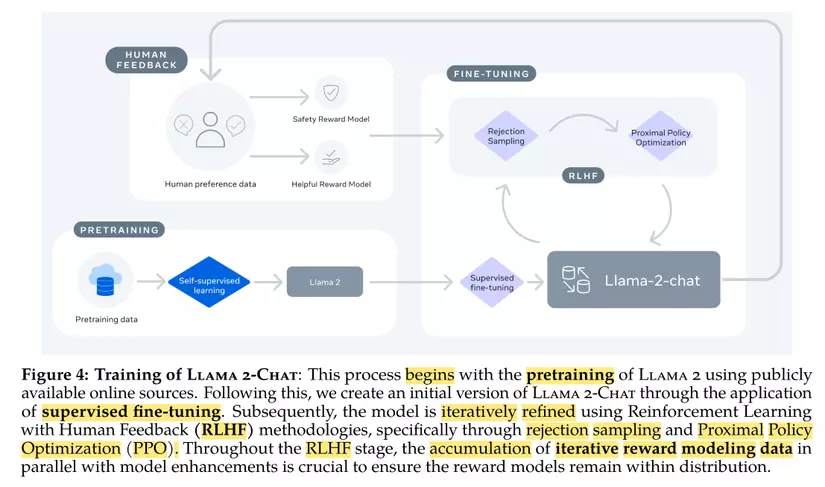
The overall process can be summarized in three steps:
- Pretraining: Train a foundational model using readily available online data sources, leveraging techniques like self-supervised learning seen in the original Transformer models.
- Supervised Finetuning: Develop an initial version of LLaMa-2-Chat using labeled data sets. This data includes prompts and their corresponding responses.
- RLHF: The model then undergoes continuous refinements using the RLHF technique, employing algorithms like PPO and Rejection Sampling. Throughout the RLHF process, the model's reward computation is constantly updated, ensuring that it aligns with the Chat model's data distribution. Let's delve into the details of each section in the paper.
Pretraining
The initial step, Pretraining, involves training the transformer model on a vast data set using self-supervised learning techniques. This method enables the model to learn intrinsic dataset features through direct data transformations. For instance, masking certain words in a sentence and prompting the model to predict the masked words. The unique aspect here is that they further incorporated about 40% more data from various sources, dedicating significant effort to filter out potentially harmful personal information. This has resulted in a fairly clean dataset of approximately 2 trillion (or 2000 billion) tokens. The Transformer model was trained using the AdamW algorithm and incorporated a learning rate scheduler with an initial warm-up of 2000 steps. Interestingly, after training with 2 trillion tokens, the training loss hadn't plateaued, suggesting potential improvements with more data and training time. Nonetheless, the current LLaMa version already outperforms many open-source models across different benchmarks. While it contends well against closed-source LLMs like ChatGPT, it lags notably behind GPT-4. Yet, given community advancements, we can anticipate newer LLaMa versions that'll rival those closed-source LLMs. Let's stay tuned for those.
Supervised Finetuning
Data quality is paramount when fine-tuning models. However, using millions of third-party SFT data from diverse sources can raise concerns regarding diversity and quality. Instead, the authors emphasized using a smaller but higher-quality dataset curated by their team. The results indicated that approximately 10,000 data samples sufficed for effective outcomes. After having a pretrained model, the authors proceeded with fine-tuning for chat data, using instruction tuning with public data to bait the model. This fine-tuning process operated with a batch size of 64 and a sequence length of 4096. To ensure full sequence length utilization, all training set questions and answers were concatenated using a special token, distinguishing the question and answer portions. Backpropagation was only executed on the answer tokens, and the model was fine-tuned over two epochs.
Implementing RLHF
One of the standout features in this paper is how Meta demonstrated the use of the RLHF technique to enhance model quality. It's not just abstract concepts or vague theories like in other GPT-4 reports; it's detailed.
The primary aim of training LLM (Language Learning Model) is to align or adjust the model to human preferences and behaviors. To achieve this alignment, the RLHF technique is proposed. With RLHF, two factors are crucial:
- Reinforcement Learning: At its core, Reinforcement Learning (RL) is a machine learning technique that trains models to maximize a specific reward. In the LLM context, this reward can be perceived as human emotions: whether they find the chatbot's response enjoyable, surprising, useful, or natural. However, a challenge here is that while rewards in scenarios like gaming are straightforward to quantify, it's much trickier in the case of LLM, where the reward function is more subjective.
- Human feedback: This refers to human evaluations of model outputs, quantified with specific scores. These scores train a computational model called the Reward Model. It's essential to note that the Reward Model is at the heart of the RLHF technique. Meta invested significant effort into developing an effective Reward Model. We'll delve deeper into how they created such a model in subsequent sections.
Once the reward model, which is also a neural network, is established, popular RLHF training strategies are employed:
- PPO
- Rejection Sampling
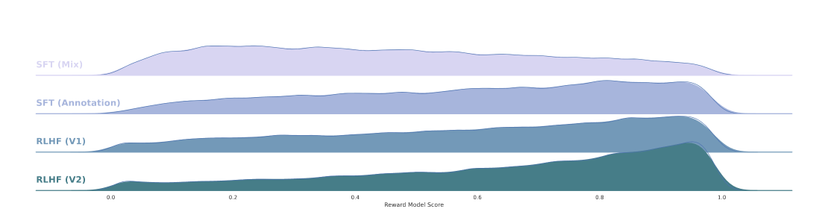
During tuning, the reward model continuously updates with new data. Before discussing the reward model training process, let's explore how they constructed the dataset. RLHF brings the model closer to real-world distributions. Onscreen, one can notice the distribution shift from models trained with Supervised Fine-tuning to the RLHF distribution. The RLHF distribution appears more human-like.
Data Handling
A notable point in this paper is Meta's acknowledgment that the most crucial aspect of training an LLM using the RLHF method lies in Reward Modeling. Past speculations on Twitter from those associated with OpenAI hinted that the success of models trained with RLHF depends largely on learning the reward function. Put simply, the key to RLHF is the reward model. We know that Reinforcement Learning algorithms require a reward function. While rewards are easily defined for some tasks, evaluating the usefulness of generated text is more qualitative. Therefore, designing an appropriate reward function for text evaluation was a significant challenge. Meta put in a lot of effort to develop datasets that reflect human-understood high rewards, termed preference data.
To summarize their data processing:
- They collected binary comparisons from human annotators. For each input prompt, two responses were produced. Annotators evaluated and chose one of the two. Qualitative ratings like significantly better, better, slightly better, or negligibly better/unsure were also provided.
- They employed multi-turn preferences, meaning responses from different model checkpoints combined with temperature parameter variations were used to diversify the answers to a prompt. Such diversity is beneficial for subsequent RLHF model training.
- They focused on addressing two issues they hoped LLaMA-2 would resolve: helpfulness and safety, using separate guidelines for each data vendor. Safety of the generated responses was prioritized. In the paper, the authors utilized safety metadata during training, ensuring no unsafe data was incorporated into finetuning. The exact purposes and other types of metadata were not detailed, but it's speculated that other metadata types, such as potentially misleading prompts, might exist.

- They collected data in weekly batches, which aided in managing data distribution. Meaning, every week, a new batch of data was used to train both the reward model and chat model, minimizing distributional discrepancies in data. As the reward model improved, so did the Chat model's quality.
Reward Modeling
Training Approach
As mentioned above, the success of the RLHF technique heavily depends on training a robust reward model. In this paper, the authors delve deep into constructing the reward model. They introduce two distinct reward models:
- One model specifically targets safety, while the other focuses on helpfulness.
- The scaling law is employed to determine the data volume and resources required for training the reward models.
To clarify further, the paper mentions that the reward model is of two kinds: one optimized for safety and the other for helpfulness. Both models are built upon the chat model (i.e., LLaMa-2-CHAT). The only difference is they've replaced the language model's heads (next-token prediction) with a regression head to produce scalar outputs. The rationale for using the same base model as the chat model is to ensure that the reward model "understands" the chat model, implying they share the same core knowledge, which avoids any misaligned inference. Hence, they utilize the most recent chat model checkpoints as the foundation for the reward model.
Training Tips
Here are some technical pointers worth noting:
- Data Compilation: They combined open-source data with their annotated data for training the reward model. However, in the initial stages, only open-source data was used. They found that the open-source data didn't negatively impact the RLHF results, so they retained it for subsequent training sessions.
- Retaining 90% of Anthropic's harmlessness data mixed with 10% from Meta wasn't explained. Why only 10% from Meta? Could it be to develop a stronger model?

- Only training for one epoch with each data update to prevent overfitting.
- The average accuracy of the reward model is approximately 60 - 70%, as per the paper. For instances deemed Significantly Better, the accuracy peaks at around 90%. This makes sense as these are classes humans are most decisive about. But for categories that even humans are unsure of, the model's accuracy is roughly 50% (akin to a random choice). This might seem low, but it genuinely reflects human behavior. After all, humans too are often indecisive, making it challenging to judge which is superior, right?
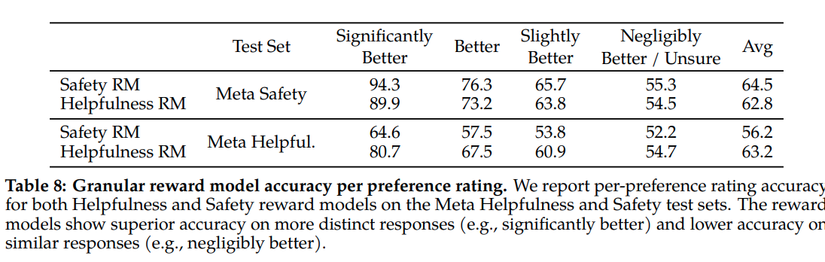
- Training involves ranking loss and incorporates a margin parameter to aid the model in learning effectively across varying score levels.
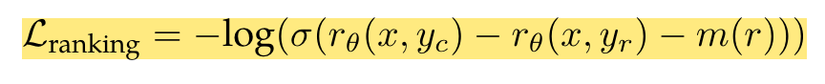
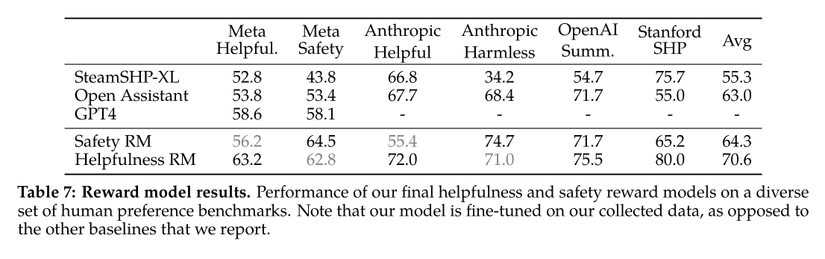
- The authors evaluated their model against GPT-4 using a zero-shot prompt: Choose the best answer between A and B, where A and B represent model-generated responses. Results indicate that the authors' reward model outperforms GPT-4. However, reward models trained solely on public datasets did not fare as well as GPT-4.
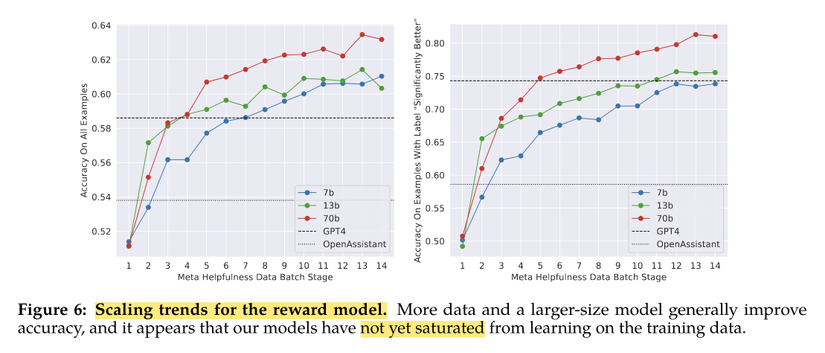
The chart below illustrates the accuracy growth of the reward model as more data gets added. Their data partners send data in weekly batches.
Discussion on the sidelines
The outcomes of the reward model are extremely crucial and significantly influence the accuracy of the model, playing a major role in the RLHF strategy. This is probably why we haven't seen any entity open-source their reward model. Even in the source code for Llama-2, this part is NOT OPEN-SOURCED. Perhaps that's understandable given the high costs involved in developing a robust reward model.
Model Safety
Over half of the paper addresses how to ensure the model's safety. The safety aspect of this model, and the report itself, represents a significant advancement compared to available open-source models. I was genuinely surprised at how well Falcon 40b-instruct performed in this area, knowing that its training process was relatively relaxed. But discussing this further is beyond the scope of this article.
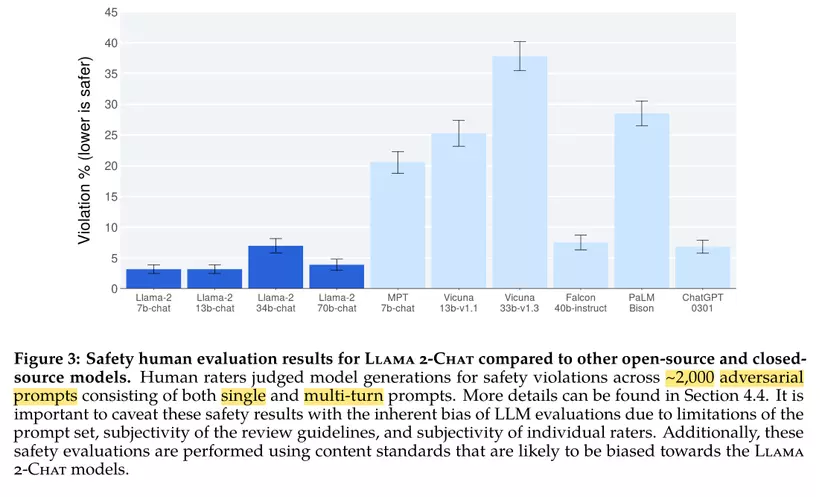
Personally, I haven't paid much attention to safety levels or comparing safety across different models. We use them for free, and I respect the efforts of the authors behind these models. Ensuring safety is our responsibility when productizing them. One concern is whether the safety assessments are too sensitive, given that the 34B version wasn't released even though it followed a similar training approach.
Astronomical Costs
Just the data costs for LLaMa-2 are estimated to be around $8 million. So, personally, the dream of training an LLM on my own is simply OUT OF REACH. I'm genuinely grateful to Meta for generously funding the creation of a language model that can be considered one of the best in the open-source LLM world. Long live Meta!
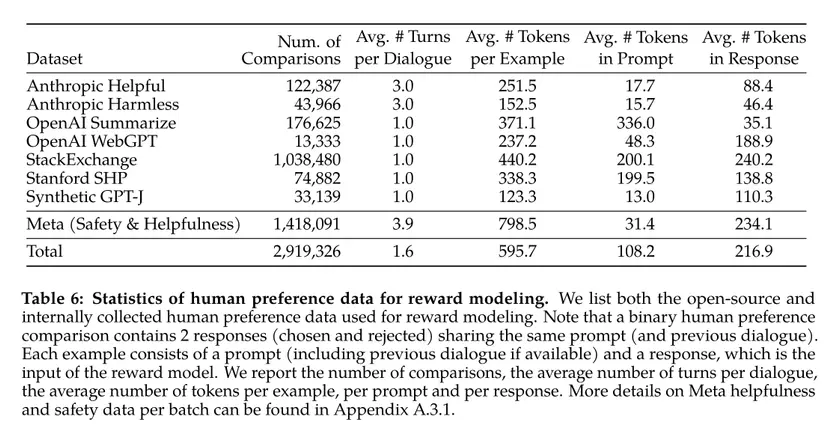
Below are statistics of datasets used for human preference data in training reward modeling. It consists of nearly 3 million samples, including prompts and corresponding responses.
As for the costs associated with GPUs, the paper specifies the exact numbers. They consumed nearly 3.4 million GPU hours. Imagine if you had just one GPU to train this model; it would take about 141,666 days or 388 years to complete the training on LLaMa. Each of their GPUs is an NVIDIA A100s, and their cluster is estimated to contain around 6000 GPUs. Just calculating the costs to purchase this GPU setup reaches into the millions of dollars. It's an amount only elite businesses can afford.
Environmental Impact
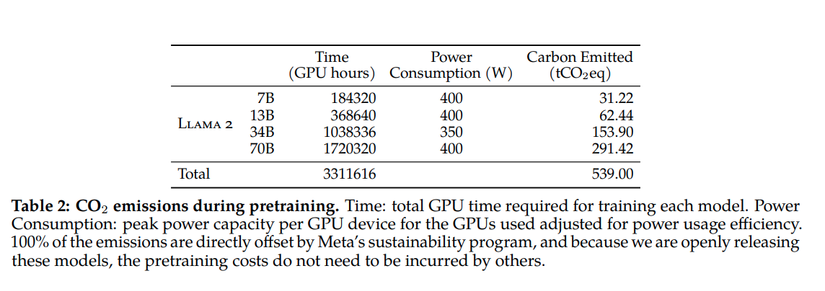
This is also the first paper discussing the power consumption and carbon emissions for training. It consumed approximately 3.3 million GPU hours, equating to about 1.3 million KW of power and releasing 539 tons of CO2 into the atmosphere. This is a figure worth noting.
Conclusion
This is an excellent technical report from a technical standpoint, and it's clear that Meta is putting in a lot of effort to democratize AI. With the introduction of LLaMa-2, I believe we'll see many more improved versions with community contributions. This might also be a move to reduce the competitive advantage of rivals. Regardless, I'm thankful to Meta for answering many of my questions related to LLM













0 Comments