
Introduction
Welcome back to the article series titled "What I Know About MongoDB", focusing on the popular NoSQL DB - MongoDB.
In this article, I'll delve into the system architecture of MongoDB. By the end, you should grasp the individual components of MongoDB and their roles.
MongoDB Standalone
There isn't much to discuss regarding the "standalone" architecture since its name pretty much sums it up.
A standalone MongoDB is essentially for development, lab, or demo purposes. Typically, users are more concerned about its application rather than the database's operational mechanics.
Such standalone databases lack High Availability (HA) and scalability. Hence, in practice, Replication is used for High Availability and Sharding for easy system scaling.
Let's delve into these techniques!
Using Replication
What is Replication?
With a standalone MongoDB, if your server malfunctions, your data is interrupted, services might not connect, and data might be lost.
A natural solution is to enhance the system's fault tolerance so even if a service goes down, data loss is avoided. The answer is Replication.
The idea behind Replication is to create a replica set, a group of mongod processes maintaining a dataset. A replica set offers data redundancy and a high-availability database.
MongoDB’s architecture using a replica set is as follows:
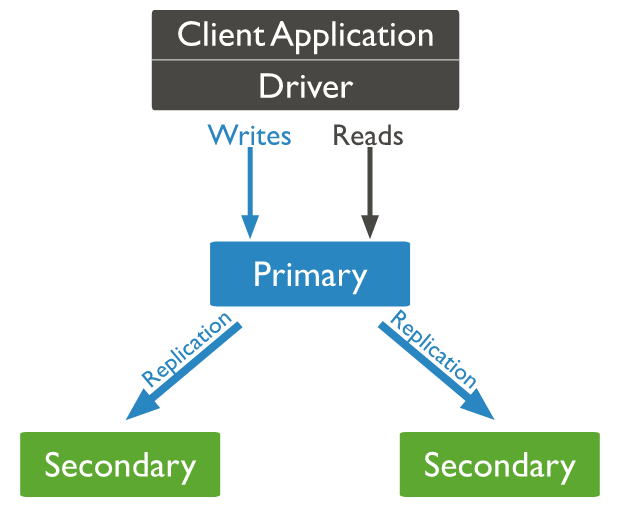
All write operations are executed on the primary node and then replicated to the secondary nodes (or replicas).
If the primary node fails, one of the remaining secondary nodes is elected as the new primary.
Some replication mechanics to note:
- A replicaset can only have one primary node, possibly several secondary nodes, and potentially one arbiter node.
- Writing to the DB is only done through the primary node, but reading can be done from secondary nodes.
- The arbiter plays a role in voting for a new primary and doesn’t store any DB data.
- An arbiter remains an arbiter, but a primary can turn into a secondary and vice-versa.
- An odd number of nodes is necessary for a primary election.
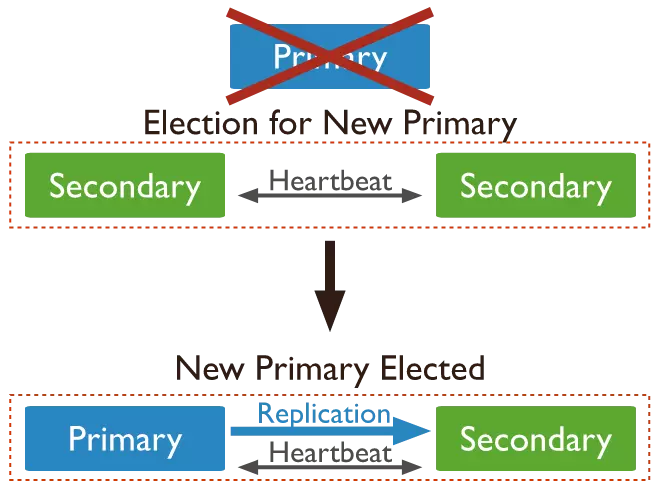
Automatic Failover
A primary node is considered faulty if it doesn't interact with other nodes in the replicaset within a set period, defined by the "electionTimeoutMillis" parameter (default is 10 seconds).
A suitable secondary node will then initiate the election of a new primary. The cluster conducts a vote to select the new primary and resumes its read/write operations. Nodes can be prioritized in this election process based on specific weightings.
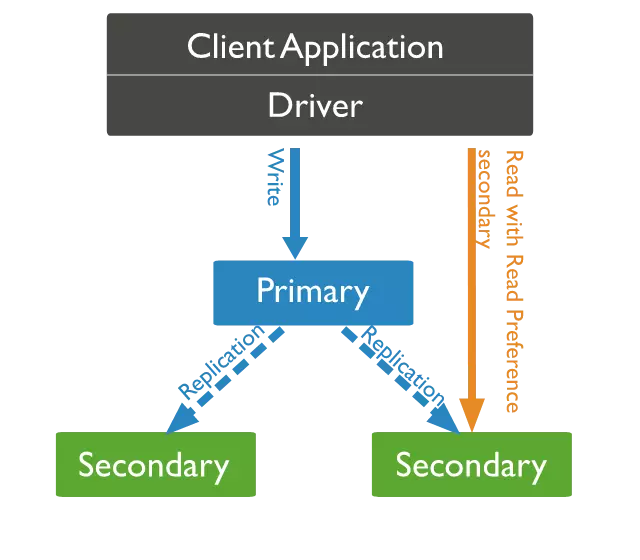
Reading Data from Secondary Nodes
By default, clients read data from the primary node. However, they can be configured to read from secondary nodes.
But note, secondary nodes synchronize data from the primary node, meaning data read from secondary nodes might not be the most recent. There might be slight disparities between the primary and secondary nodes.
Thus, carefully consider when opting to read from a secondary node.
Using Sharding
What is Sharding?
By utilizing Replication, we've already addressed data safety concerns. We no longer need to worry about data loss or service disruptions when the primary node fails.
However, as our system continues to grow, demanding more processing power or storage capacity, Replication alone won't solve this challenge. We need a solution that allows us to scale our system when necessary.
One option is Vertical scale: simply upgrading RAM/CPU/Disk for nodes. But this approach is hardware-limited since servers have finite RAM and CPU slots.
To effectively scale, MongoDB offers Sharding, which essentially breaks down database data into smaller portions (called shards) and each of these parts is managed by a separate shard server. This method is referred to as "Horizontal Scale" and is highly efficient.
So, when scaling up, we simply need to increase the number of shards and corresponding shard servers.
A MongoDB utilizing sharding is referred to as a "sharded cluster".
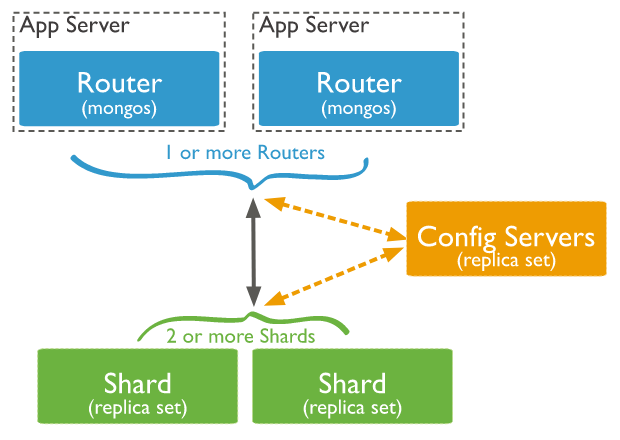
Sharding System Architecture
A MongoDB sharded cluster mainly consists of:
- shard: Each shard contains a part of the sharded data. These shards can be deployed as replicasets to enhance their data redundancy.
- mongos: Acts as a query router, interfacing clients with the sharded cluster. Clients only need to connect to mongos, which then transparently manages connections to the necessary shards or replicas.
- config servers: Hold metadata and configuration parameters for the cluster. For instance, configuration details of shards and replicasets are stored here. Config servers can also be deployed as replicasets.
Shard Keys
MongoDB uses a shard key to distribute records (documents) of tables (collections) to the respective shards. A shard key can consist of one or several fields from that table.
The selection of a shard key happens when sharding a collection. Note that once a collection is sharded, it can't be "unsharded".
Within a database, it's possible to shard only specific collections rather than every collection.
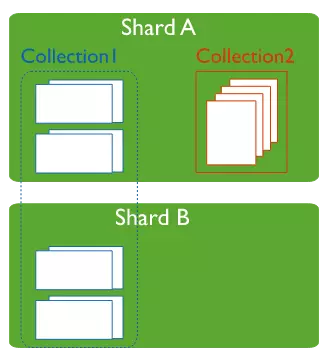
Best Practice: Combining Sharding and Replication
Both Replication and Sharding provide solutions for the challenges of a standalone MongoDB. In practice, both techniques are used in designing and deploying MongoDB clusters.
The overall architecture looks like this:
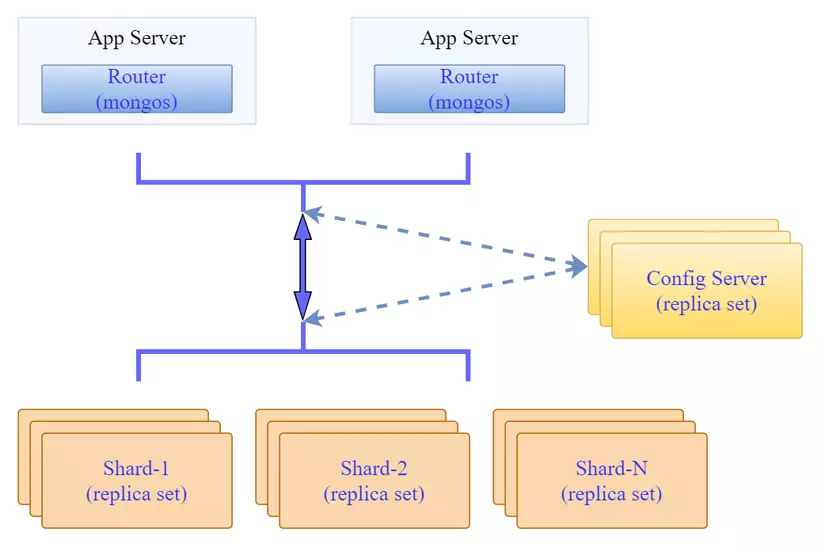
Components like the Config server and shard are implemented as replica sets. Each component ensures data redundancy, and the shards provide scalability for our MongoDB cluster.
I hope this provides a clear understanding of the basic concepts and components of a MongoDB sharded cluster. In the next article, I'll guide you on setting up a standalone MongoDB and a sharded cluster as per the above model.
If you found this article useful, please support by upvoting it to motivate me to write more!
See you in the next section!













0 Comments